Lecture 18 Virtual Memory:Systems
this lecture 主要学习虚拟内存在真实系统 Linux, x86-64下的工作情况
today's agenda
- Simple memory system example
- Case study: Core i7/Linux memory system
- Memory mapping
Simple memory system example
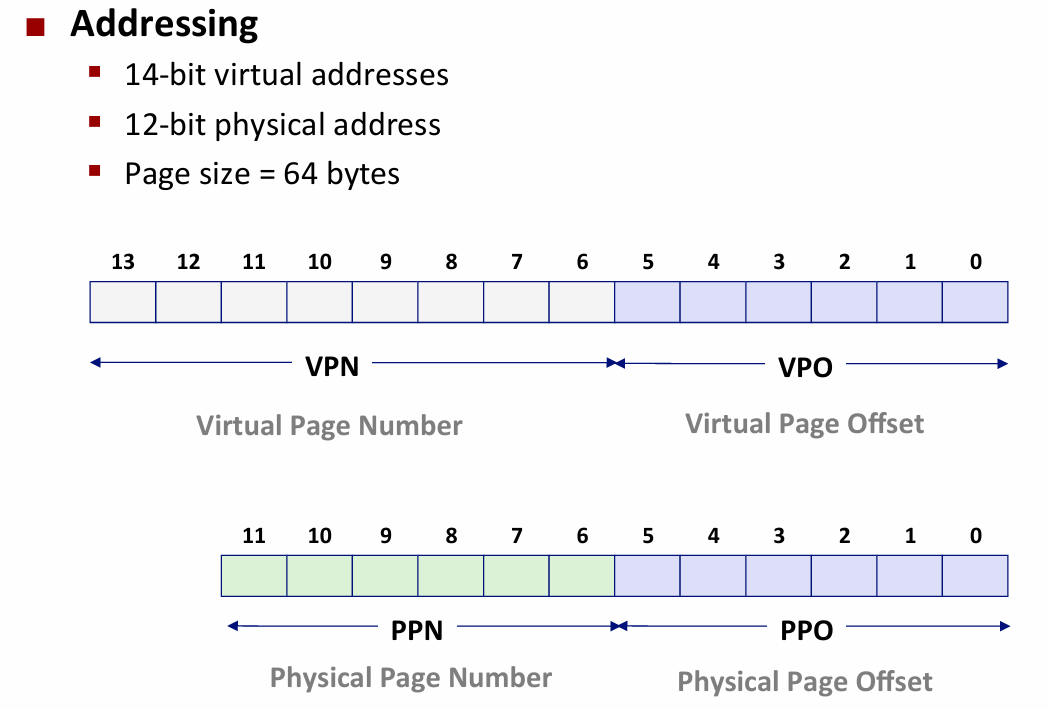
TLB 16个条目 四路组相连

所以使用 低两位作为组索引 剩下的作为标记位
page table
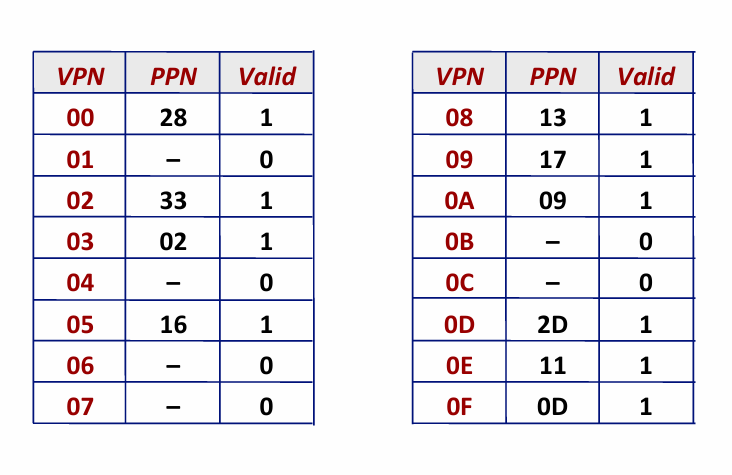
Simple Memory System Cache: 直接映射 高速缓存
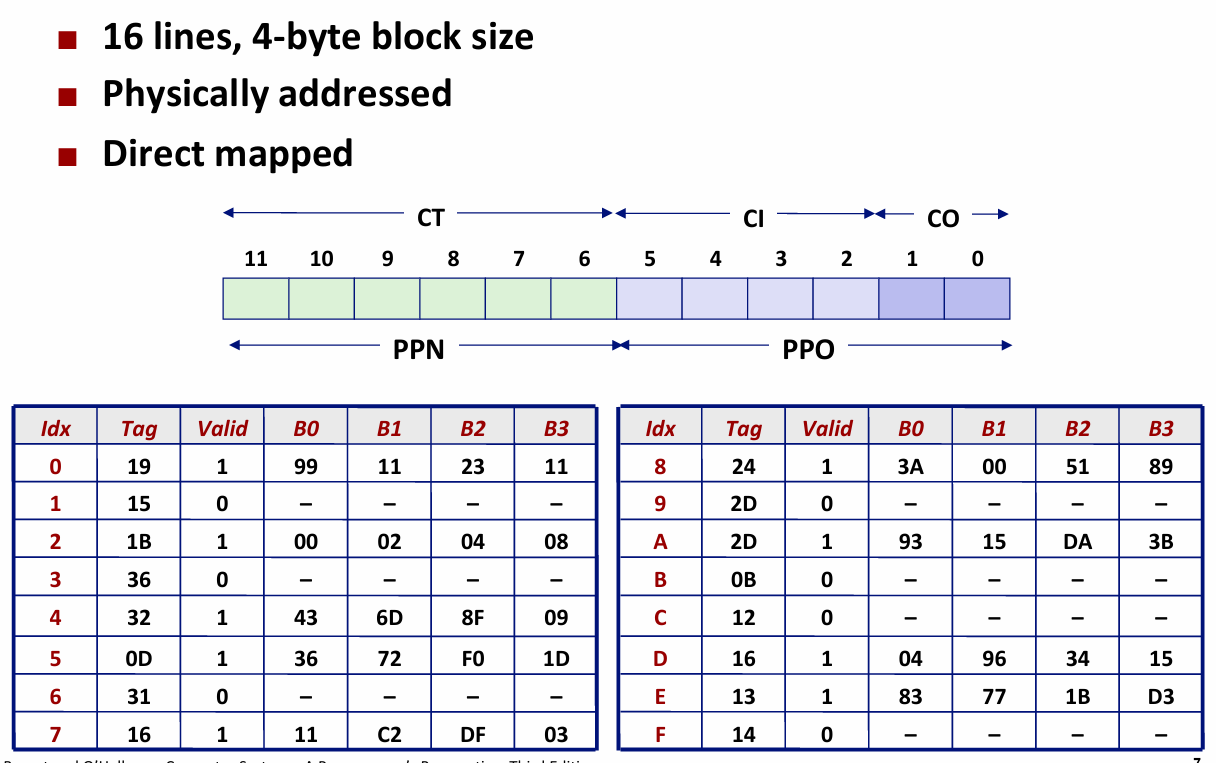
- 4-byte block size: 两位用于偏移
- 16lines: 4bit 表示索引
- 其他用作标识位
Address Transla on Example 1
假设CPU执行了一条指令 产生了一个有效地址 这个地址的虚拟地址是0x3d4 这个地址会送到MMU 然后拿到物理地址
Step1: 将这个地址表示成二进制 找到虚拟页号和虚拟页面偏移
Step2: 根据虚拟页号 查TLB
TLB Hit? -- Yes, 构造物理地址
Step 4: 查高速缓存
Hit? Yes -- 返回数据

Address Transla on Example 2
Virtual address: 0x0020

Case study: Core i7/Linux memory system
虚拟内存 在 真实系统上是如何工作的? -- 这里举的例子是Intel x86-64下的core i7
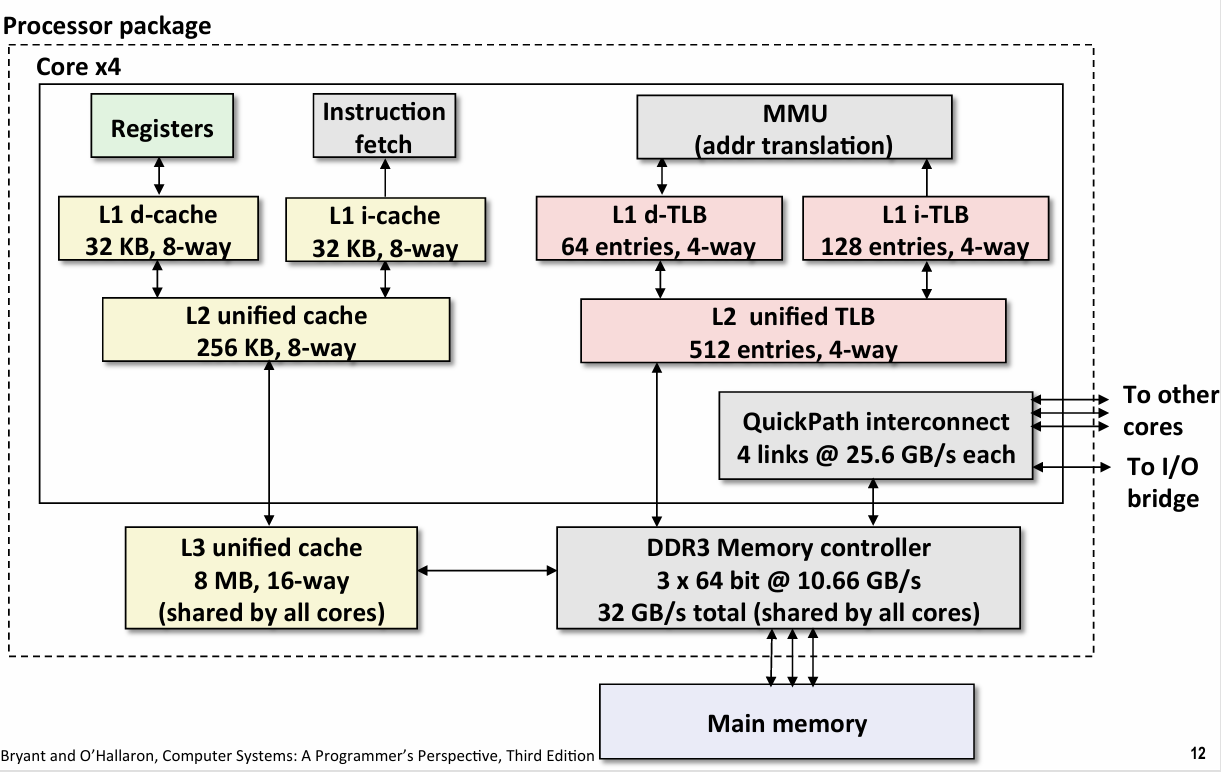
这是core i7 内存系统的结构图 -- 这是芯片的处理器封装
4 Core 每一个核心都是独立的cpu 可以独立的执行指令
每一个核心都有 register(寄存器), Instruction fetch(处理指令的硬件), 有两个L1 cache 一个是 data cache 一个是instruction cache 大约4个cycle , L2 cache 10个cycle
外面还有L3 cache 是所有核共用的 30~50 cycle
MMU TLB 也有层级结构
DDR3 Memory controller(内存控制器) -- 从内存中提取数据
QuickPath interconnect -- 连接不同核心 和 IO桥
End-to-end Core i7 Address Translation
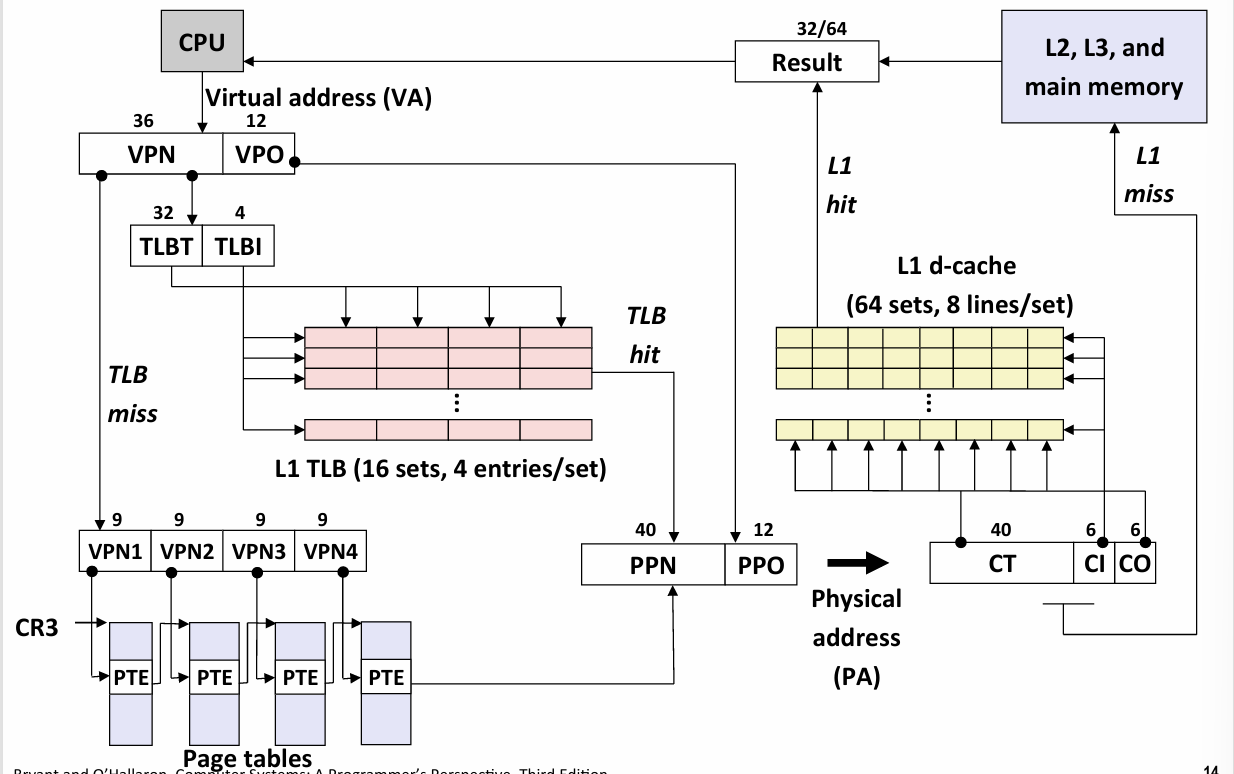
CPU产生一个Virtual address -- 在Intel系统中虚拟地址长度为48bits
page size = 4k -> 12bits -> VPN: 36bits
L1 TLB有十六组 VPN被拆分成4bits TLBI, 32bits TLBT
if TLB hit -> 生成物理地址
if TLB miss -> 去page table 取出PPN -> 生成物理地址 这里使用的是多路查表 后面会介绍具体细节
MMU把物理地址传递给高速缓存
L1 cache 有64 组 8路组相连 -> 6bits index, 这里注意偏移位和索引位的长度 CI和CO的长度刚刚好是VPO & PPO的长度 这不是一个巧合 -> 所以L1 cache比较小
if cache hit -> result
if cahce miss -> memory
if miss page -> 缺页异常 -> disk
Core i7 Level 1-3 Page Table Entries
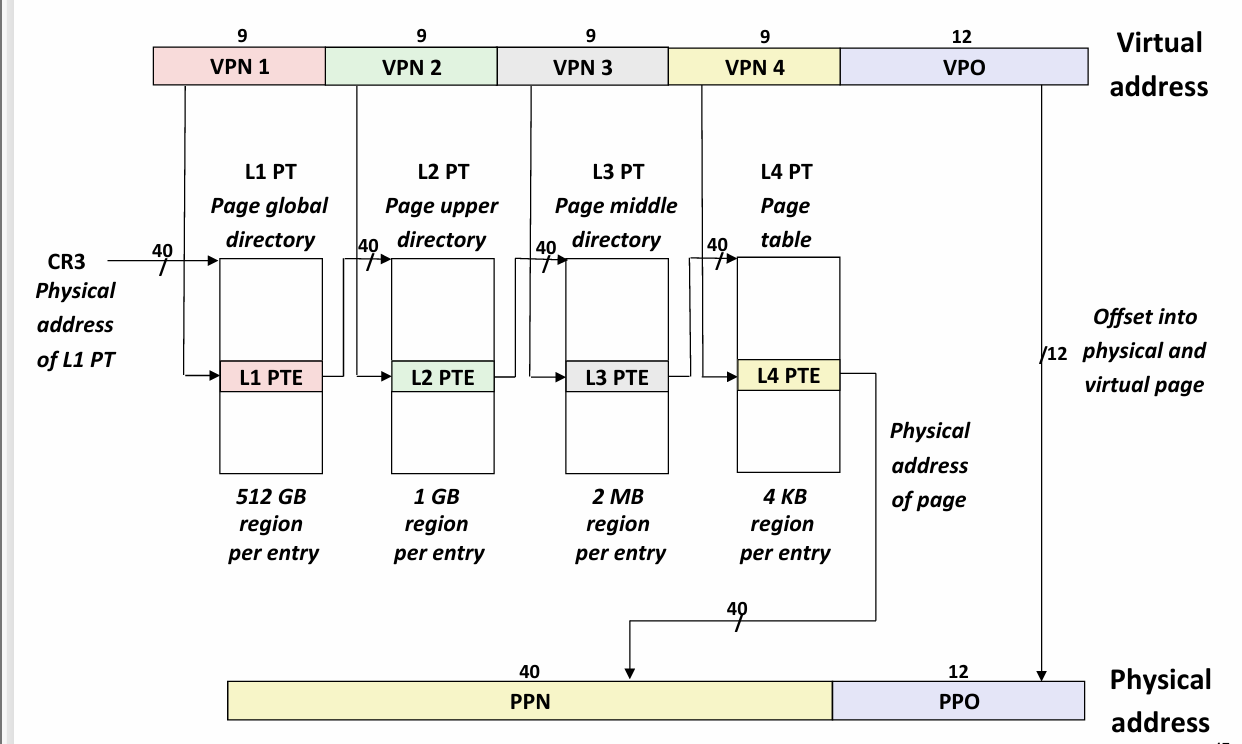
Intel Page table的结构

- p: 标识子页表是否在物理内存中
- R/W 只读 or 可读可写
- U/S: 用户 or 内核
- WT: write-through or write-back
- A: 引用位 MMU read and write时设置
- PS: page size 4KB or 4MB
- XD: 标识能不能从这个PTE可访问的所有页中指令获取? -- 现代栈系统降低收到缓冲区溢出攻击风险的一个方式 -- XD无效表明你不能从这个page中加载指令
- page table physical base address: 下一级page table的基地址
Core i7 Level 4 Page Table Entries

区别在于 page physical base address, PS, D(dirty bit, MMU读写时设置 根据这一位来决定如果将这一页作为牺牲页 要不要写回)
Core i7 Page Table Translation
Cute Trick for Speeding Up L1 Access
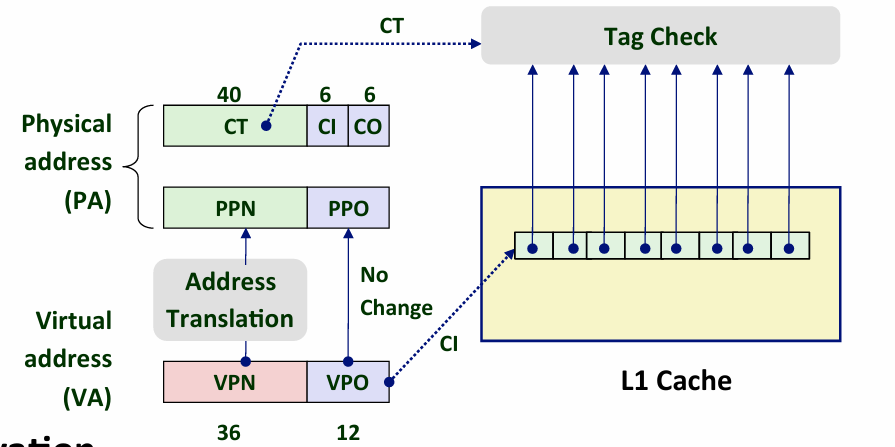
按说MMU的地址翻译应该分为两个步骤 把virtual address翻译成 physical address 然后把physical address扔到Cache中
但是Intel用了一个小技巧来提升L1 Access速度 就是故意把 CL CO PPO VPO的位数设置成一样 然后直接就把VPO扔进去了 然后其实就已经知道了 偏移量 只需要等会儿对应tag就好了-- 但这也导致了L1 Cache会很小